
pgvector’s latest release includes quantization features that help reduce your vector and index footprint while speeding up index builds and prewarming times for RAG applications. All Neon Postgres databases come with pgvector—spin up a free database here.
In this blog post, we will test how scalar quantization with halvec improves and reduces storage costs without compromising the performance and efficiency of pgvector 0.7.x indexes.
What is quantization?
Quantization is a type of compression that allows to reduction of the number of vector dimensions. There are various types of quantizations, but in this article, we will be testing two types:
- Scalar Quantization (SQ), which uses half-precision vectors
halfvecto represent floats in 16 bits instead of 32 bits used by thevectortype. - Binary Quantization (BQ), which turns each value of the vector into 0 or 1.
Learn more about quantization in pgvector in the article by Johnathan Katz.
Testing setup
For our tests, we used the DBpedia 1M 1536 dimension vector dataset on an 8CPU, 32 GB memory Neon Postgres instance running on the AWS us-east-2 region.
We measured the following:
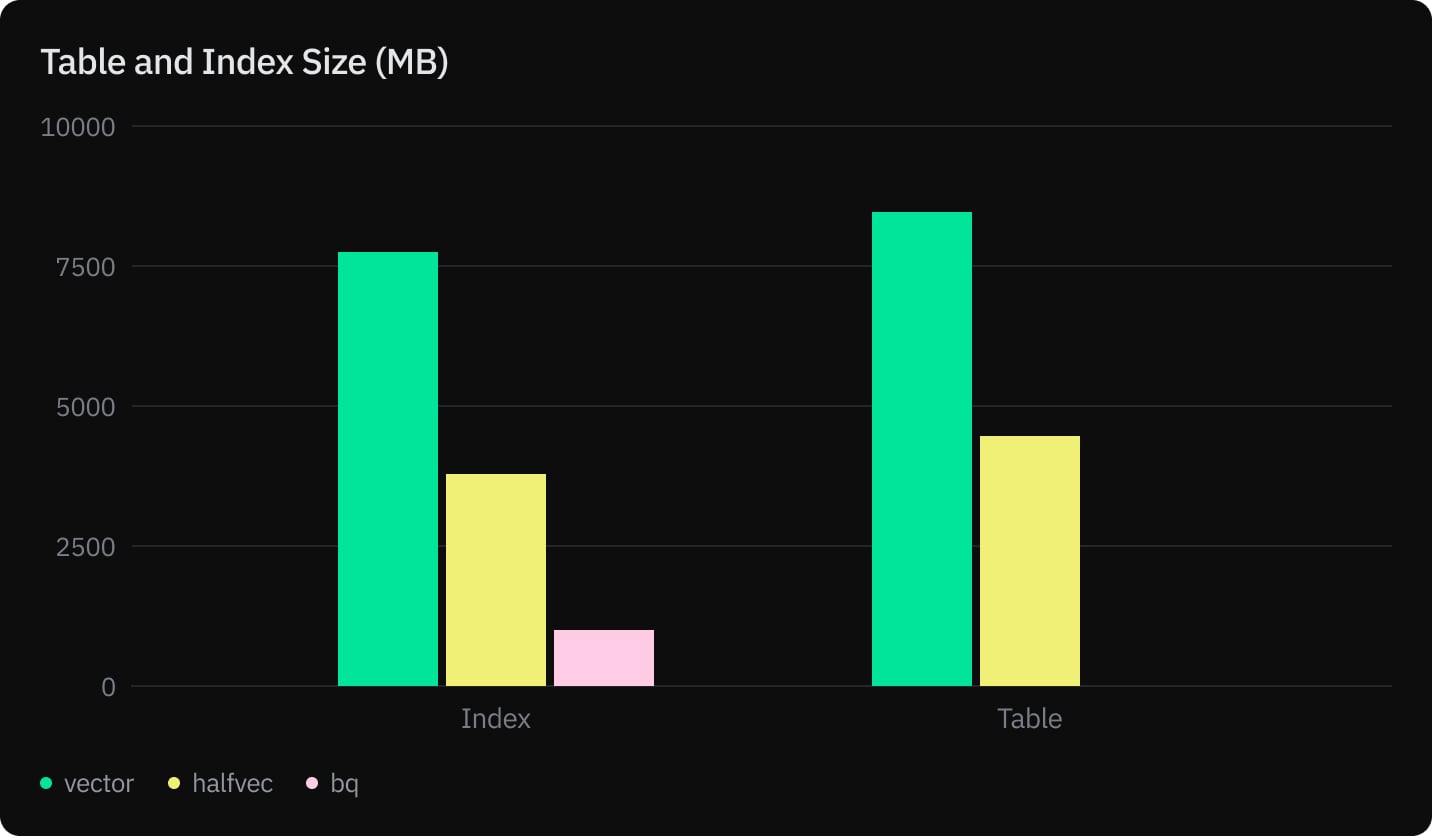
- Table and Index sizes (MB)
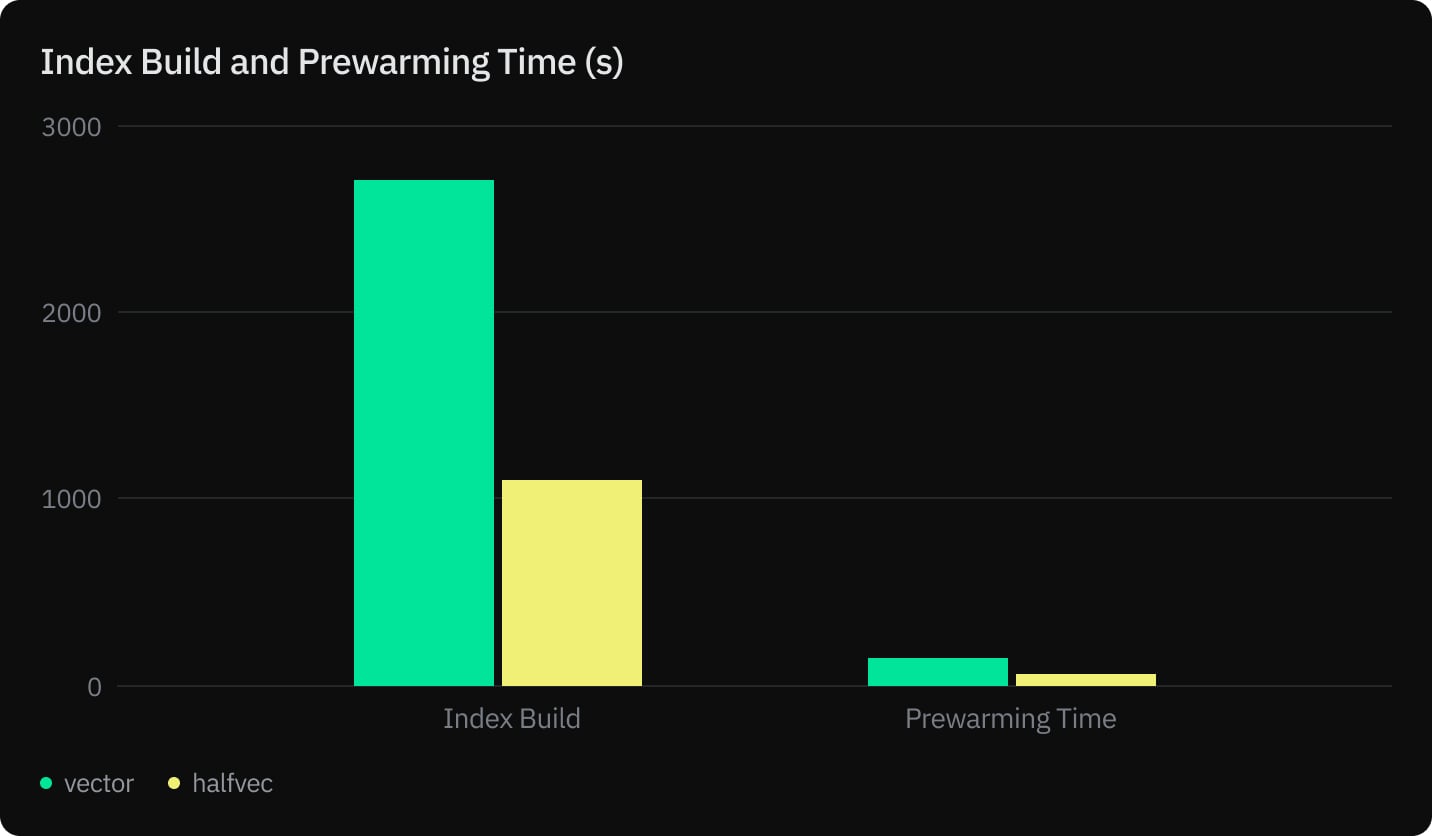
- Index Build and Prewarming Times (s)
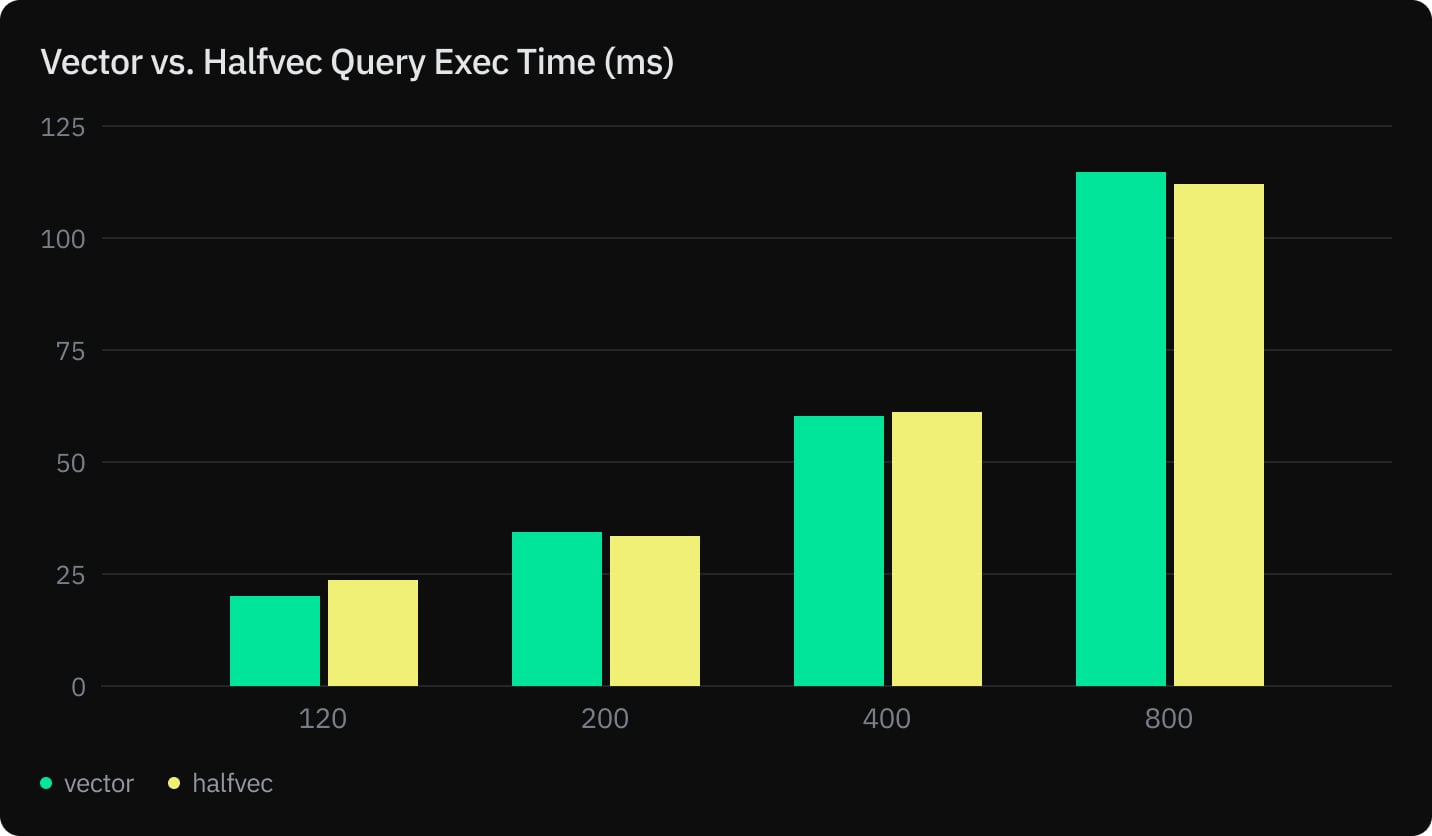
- Query Execution Time (ms)
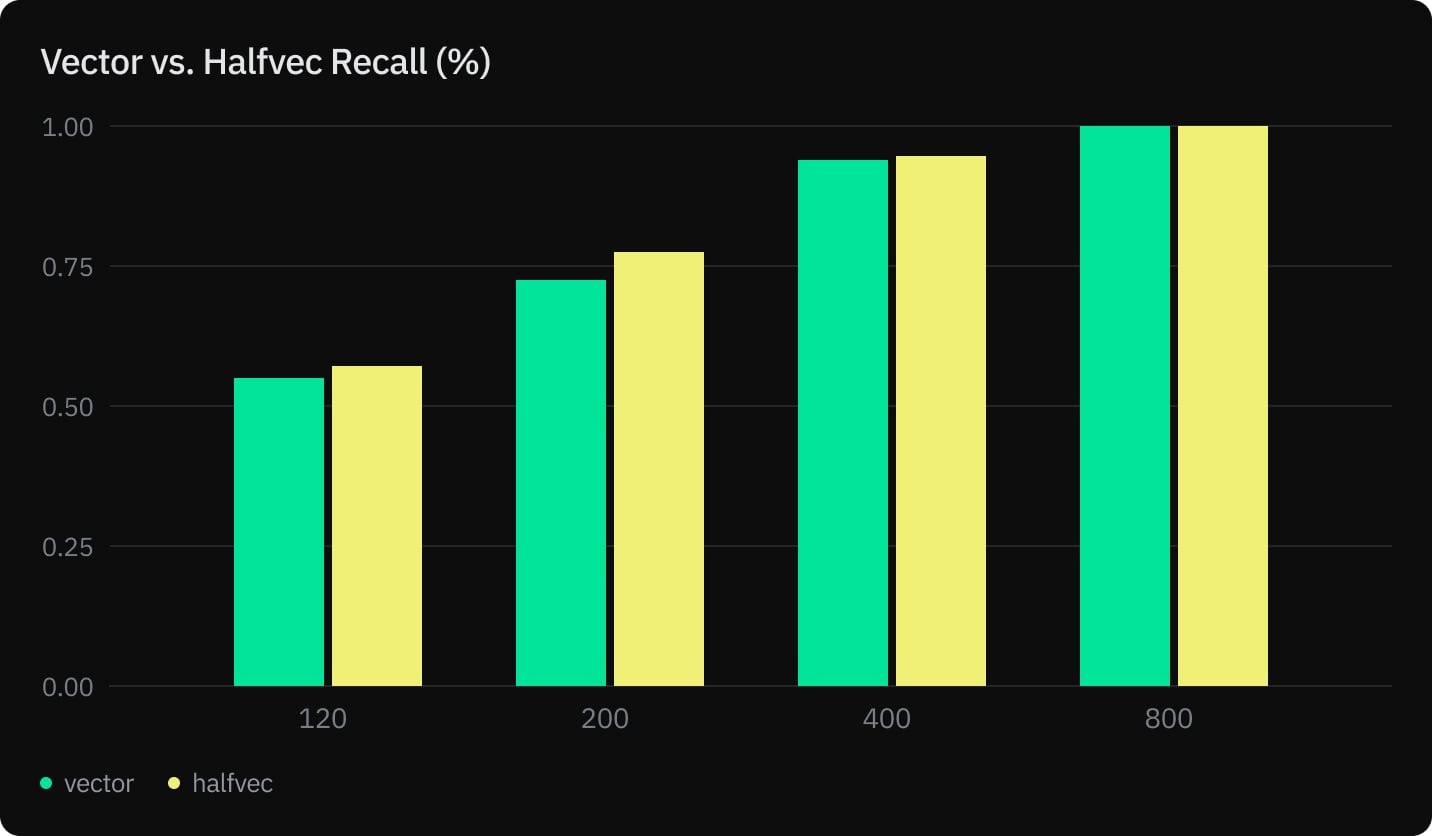
- Recall (%)
How scalar quantization improves pgvector performance
Our tests show that halfvec not only helps you reduce the memory and storage of your tables and indexes by half but also speeds up index build without compromising recall.
Specifically, the experiment shows the following benefits of adopting halfvec:
- Reducing vector storage cost by nearly 50%
- Reducing index build time by 23%
- Reducing prewarming time by 50%
- Equivalent query execution time and recall
We measured index build, prewarming, query execution, and recall for vector and halfvec using an HNSW index with m=32 and ef_construction=256.
The pgvector extension uses the vector type, an array of floats represented in 4 bytes or 32 bits. In the 0.7.0 release, pgvector adds support for the half-precision vector type, or halfvec, which uses 16-bit floating point numbers to represent its components. This reduces storage capacity in half.
For example, the value 0.123 has the following binary representation:
0∣01111011∣11110100000000000000000
- Sign bit: 0 since the number is positive.
- Exponent: 01111011. In binary, 123 is represented as 01111011.
- Significand: 11110100000000000000000. The fractional part 111101, padded to 23 bits.
On the other hand, half-precision vectors use a different binary representation of 16 bits: 1 bit for the sign, 5 bits for the exponent, and 10 bits for the significand. This means that the half-precision representation of 0.123 is:
0∣01011∣1111010000
For reference, the length of OpenAI’s text-embedding-3-small embedding vector is 1536 and requires 6148 bytes per vector (4 bytes x 1536 dimensions + 4). With halfvec, the embedding vector requires only 3076 bytes of storage or 3kB.
Testing binary quantization
Now that we have seen the improvements that half-precision vectors bring to pgvector, let’s explore binary quantization.
Binary quantization is a simple type of vector compression where each dimension is reduced to either 0 if its value is equal to or smaller than 0 or else 1.
In this case, an OpenAI text-embedding-3-small embedding vector of 1536 dimensions is represented by 1536 bits and reduced in size by a factor of 32, which reduces the index size and build time significantly.
Below, we compare HNSW index performance for vector and halfvec with and without BQ:
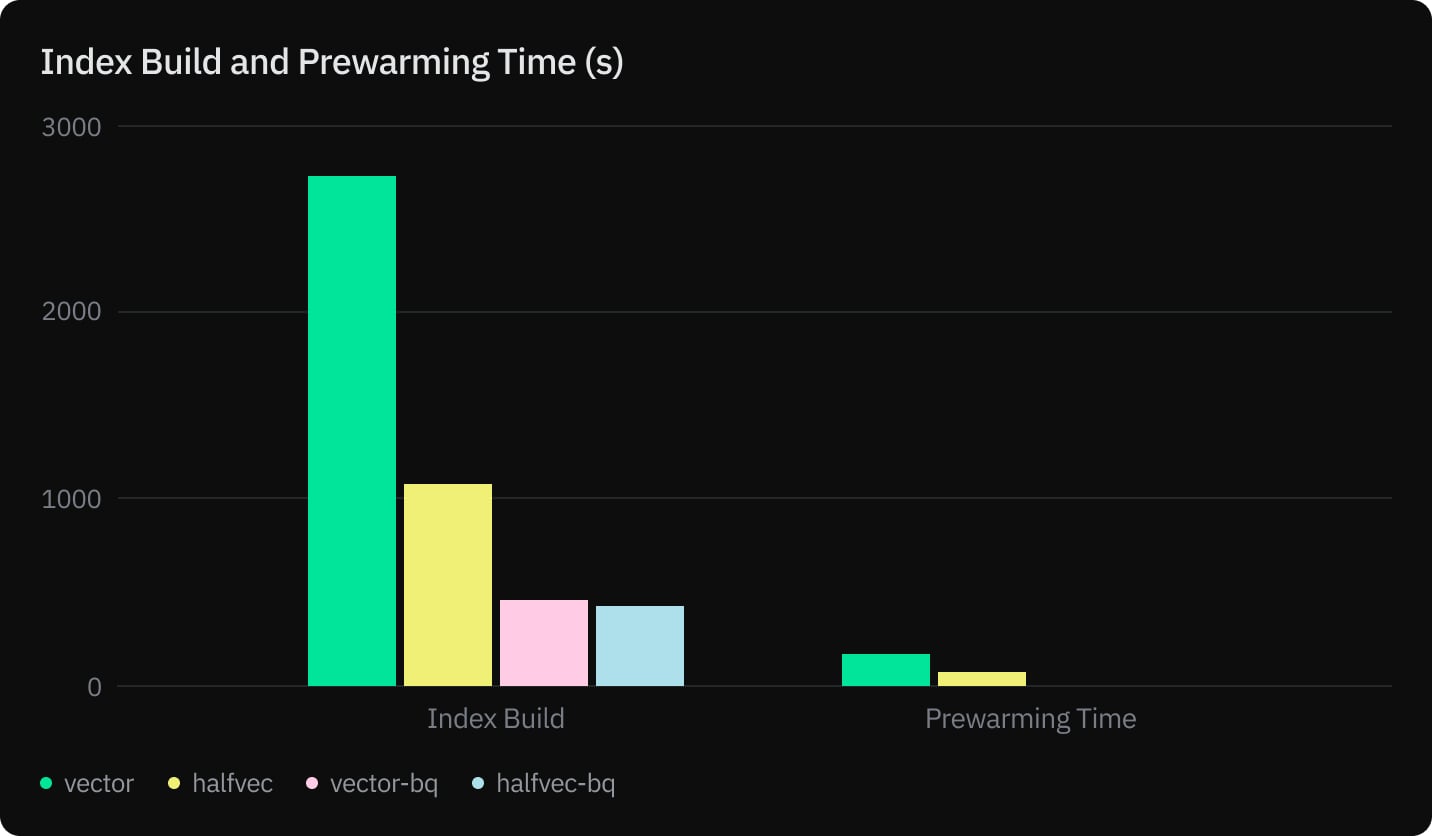
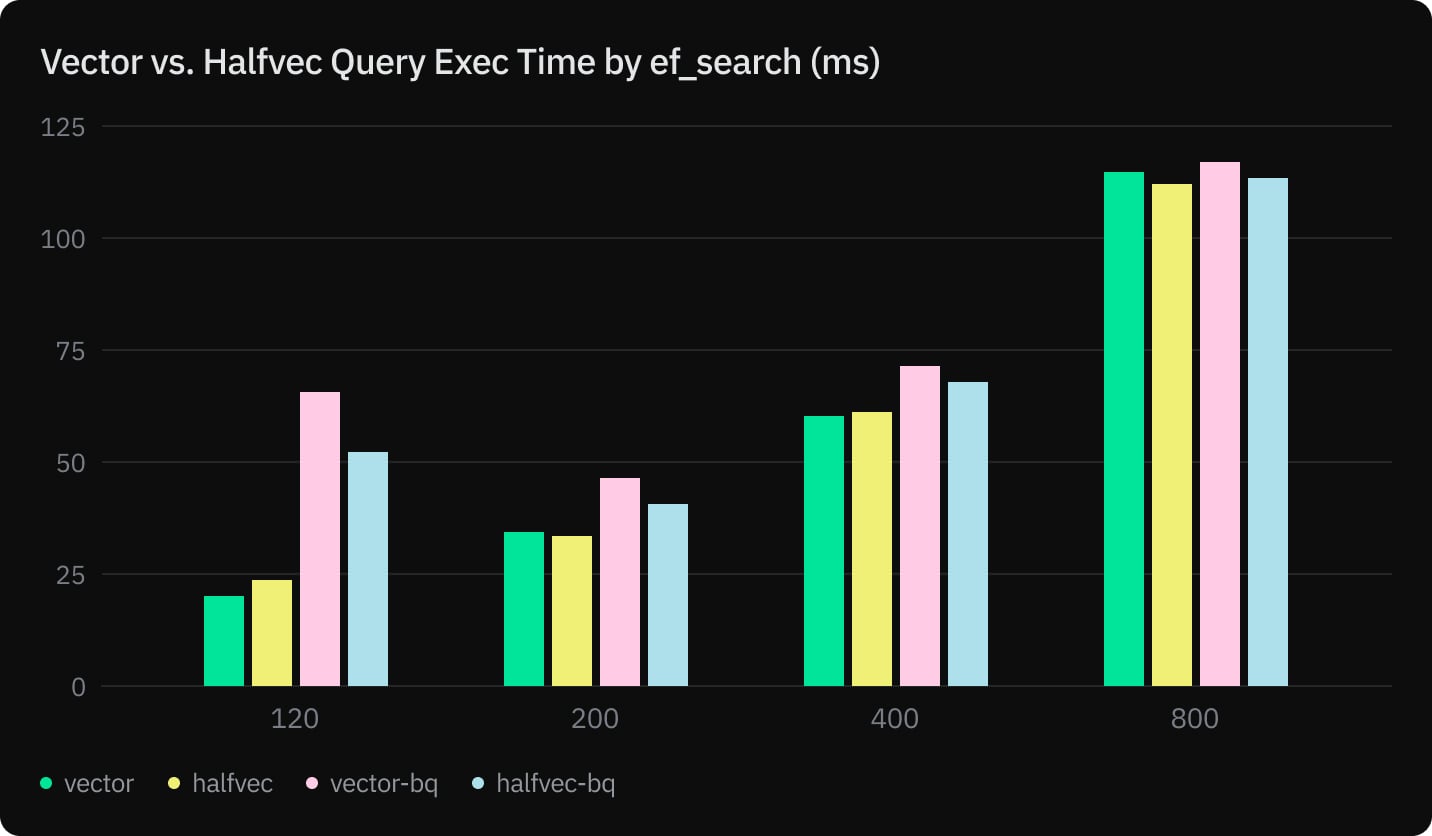
Although there are significant gains and comparable query performance, recall on the other hand with 1536 dimensional vector embeddings is not significant enough to use this in production.
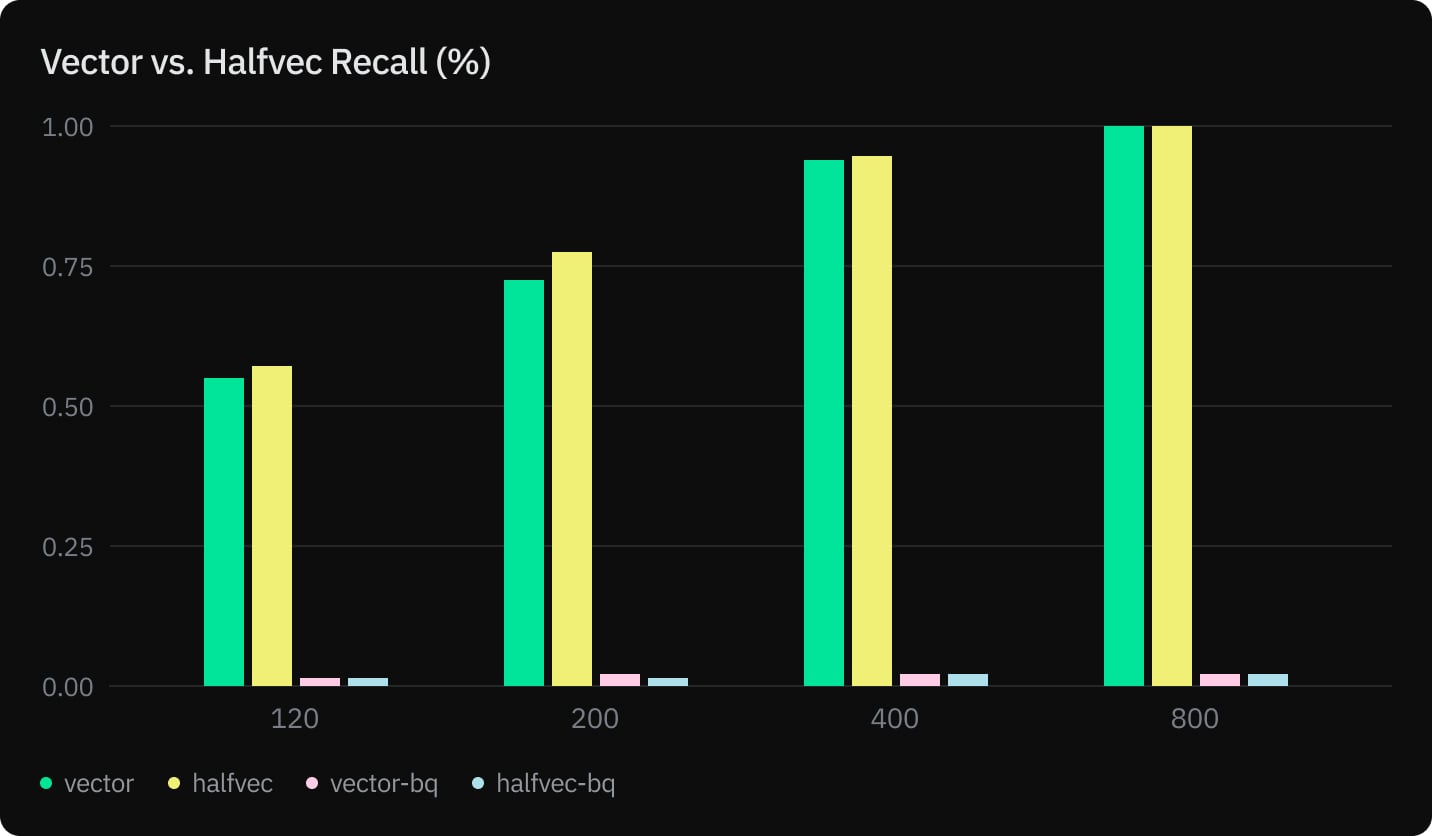
However, in an article by Johnathan Katz comparing SQ and BQ, we can see the author managed to get up to 99% recall, which might be due to the high dimensionality nature of the embedding model. In a future article, we will explore BQ further using OpenAI text-embedding-3-large with 3072 dimensions.
Conclusion
pgvector 0.7.x brings significant improvements to vector search in Postgres by introducing advanced quantization features. With the new half-precision halfvec type, you can achieve a 50% reduction in vector and index storage while speeding up index builds and prewarming times.
Taking into account these results, using SQ and the halfvec type over vector seems like an obvious choice. However, we highly encourage you to experiment with halfvec before migrating since your results might depend on your dataset.
BQ, on the other hand, didn’t result in a good enough recall with embedding vectors of 1536 dimensions. Further experiments with other embedding models and vector lengths are required before reaching a final conclusion.
What about you? What embedding models are you using? Are you using pgvector 0.7.0 and halfvec? Join us on Discord, follow us on X, and let us know what you think.



